Introduction
This post belongs to a series, you can find other parts here
The source code will be available on github.com/cedmundo/slang-sdl3-example, feel free to fork it and use it as you find suitable in your projects.
Storage buffers
Storage buffers let us bind custom data to our shaders, in slang we’ll receive them as StructuredBuffers into our shaders, the main distiction is that we need to bind them instead of passing their values by attributes.
A good way to demonstrate this feature, is by adding instances: we want to draw
the same object in multiple places with some variation. Let’s create a new entity
called QuadGroup that is basically a way to handle many SingleQuad states,
however we still need to update the single quad to allow rending multiple instaces
with a bounding buffer for their positions (usually you may want to pass the transform,
but this example is going to be simpler).
Let’s first update our vertex shader to include the instance data for each quad:
struct VSInput {
float3 position : POSITION;
float3 color : COLOR;
float2 uvs : TEXCOORD0;
uint instanceID : SV_InstanceID;
};
struct VSOutput {
float4 position : SV_Position;
float3 color;
float2 uvs;
};
struct InstanceData {
float2 position;
}
// Set 0 is for storage buffers
layout(set = 0, binding = 0) StructuredBuffer<InstanceData> instances;
[shader("vertex")]
VSOutput main(VSInput input) {
VSOutput output;
float3 instance_position = float3(instances[input.instanceID].position, 0.0f);
output.position = float4(input.position + instance_position, 1.0f);
output.color = input.color;
output.uvs = input.uvs;
return output;
}
Next, we need to update the quad module to include this buffer. For our header quad.h, update
the RenderSingleQuad definition:
void RenderSingleQuad(SingleQuad* quad,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPURenderPass* render_pass,
SDL_GPUBuffer** storage_buffers,
size_t storage_buffers_count,
size_t instances_count);
Then, we can update the implementation:
void RenderSingleQuad(SingleQuad* quad,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPURenderPass* render_pass,
SDL_GPUBuffer** storage_buffers,
size_t storage_buffers_count,
size_t instances_count) {
if (storage_buffers != NULL) {
SDL_BindGPUVertexStorageBuffers(render_pass, 0, storage_buffers, storage_buffers_count);
}
SDL_BindGPUVertexBuffers(render_pass, 0, quad->buffer_bindings, 3);
SDL_BindGPUIndexBuffer(render_pass, &quad->buffer_bindings[INDICES_BINDING_IDX],
SDL_GPU_INDEXELEMENTSIZE_32BIT);
SDL_PushGPUFragmentUniformData(cmdbuf, 0, &quad->frag_uniforms, sizeof(QuadFUniformData));
SDL_BindGPUFragmentSamplers(render_pass, 0, &quad->texture->sampler_binding, 1);
SDL_DrawGPUIndexedPrimitives(render_pass, quad->indices_count, instances_count, 0, 0, 1);
}
Here, we can see that we can render both single instance and multiple instances of the object, if we pass NULL and 1 for the last two parameters then we will be rendering a single quad, however it will be shown on the screen center and won’t be able to change.
Now we continue adding a new module called QuadGroup, it will be just a layer on top of single quads
to keep track of some state data:
Our header quad_group.h will be something like this:
#ifndef QUAD_GROUP_H
#define QUAD_GROUP_H
#include "quad.h"
typedef struct {
float position[2];
} QuadInstanceData;
typedef struct {
float origin[2];
float angle;
float speed;
float radius;
} QuadInstanceState;
typedef struct {
SingleQuad* single_quad;
size_t instance_count;
Uint64 last_tick;
QuadInstanceData* instances;
QuadInstanceState* states;
SDL_GPUBuffer* buffer;
} QuadGroup;
QuadGroup* CreateQuadGroup(SDL_GPUDevice* device, size_t instance_count);
void DestroyQuadGroup(QuadGroup* group, SDL_GPUDevice* device);
void UploadQuadGroupStatic(QuadGroup* group, SDL_GPUDevice* device, SDL_GPUCopyPass* copy_pass);
void UploadQuadGroupFrame(QuadGroup* group, SDL_GPUDevice* device, SDL_GPUCopyPass* copy_pass);
void UpdateQuadGroup(QuadGroup* group);
void RenderQuadGroup(QuadGroup* group,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPURenderPass* render_pass);
#endif /* QUAD_GROUP_H */
Then our implementation quad_group.c will look like:
#include "quad_group.h"
#include "quad.h"
#include <SDL3/SDL_gpu.h>
#include <SDL3/SDL_stdinc.h>
#include <SDL3/SDL_timer.h>
QuadGroup* CreateQuadGroup(SDL_GPUDevice* device, size_t instance_count) {
QuadGroup* group = SDL_malloc(sizeof(QuadGroup));
if (group == NULL) {
return NULL;
}
size_t instance_data_buf_size = sizeof(QuadInstanceData) * instance_count;
group->instance_count = instance_count;
group->single_quad = CreateSingleQuad(device);
if (group->single_quad == NULL) {
DestroyQuadGroup(group, device);
return NULL;
}
SDL_GPUBufferCreateInfo buffer_create_info = {0};
buffer_create_info.size = instance_data_buf_size;
buffer_create_info.usage = SDL_GPU_BUFFERUSAGE_GRAPHICS_STORAGE_READ;
group->buffer = SDL_CreateGPUBuffer(device, &buffer_create_info);
group->last_tick = SDL_GetTicks();
group->instances = SDL_malloc(instance_data_buf_size);
if (group->instances == NULL) {
DestroyQuadGroup(group, device);
return NULL;
}
group->states = SDL_malloc(sizeof(QuadInstanceState) * instance_count);
if (group->states == NULL) {
DestroyQuadGroup(group, device);
return NULL;
}
// Randomize staring positions
for (size_t i = 0; i < instance_count; i++) {
float x = SDL_randf() * 0.8f - 0.5f;
float y = SDL_randf() * 2.0f - 0.5f;
float r = SDL_randf() * 0.3f - 0.2f;
float s = SDL_randf() + 0.4f;
group->states[i].origin[0] = x;
group->states[i].origin[1] = y;
group->states[i].speed = s;
group->states[i].angle = 0.0f;
group->states[i].radius = r;
group->instances[i].position[0] = x;
group->instances[i].position[1] = y;
}
return group;
}
void DestroyQuadGroup(QuadGroup* group, SDL_GPUDevice* device) {
if (group == NULL) {
return;
}
if (group->buffer != NULL) {
SDL_ReleaseGPUBuffer(device, group->buffer);
}
if (group->instances != NULL) {
SDL_free(group->instances);
}
if (group->states != NULL) {
SDL_free(group->states);
}
if (group->single_quad != NULL) {
DestroySingleQuad(group->single_quad, device);
}
SDL_free(group);
}
void UploadQuadGroupStatic(QuadGroup* group, SDL_GPUDevice* device, SDL_GPUCopyPass* copy_pass) {
UploadSingleQuad(group->single_quad, device, copy_pass);
}
void UploadQuadGroupFrame(QuadGroup* group, SDL_GPUDevice* device, SDL_GPUCopyPass* copy_pass) {
size_t instance_data_buf_size = sizeof(QuadInstanceData) * group->instance_count;
SDL_GPUTransferBufferCreateInfo transfer_buffer_create_info = {0};
transfer_buffer_create_info.size = instance_data_buf_size;
transfer_buffer_create_info.usage = SDL_GPU_TRANSFERBUFFERUSAGE_UPLOAD;
SDL_GPUTransferBuffer* transfer_buffer =
SDL_CreateGPUTransferBuffer(device, &transfer_buffer_create_info);
void* gpu_staging = SDL_MapGPUTransferBuffer(device, transfer_buffer, false);
SDL_memcpy(gpu_staging, group->instances, instance_data_buf_size);
SDL_UnmapGPUTransferBuffer(device, transfer_buffer);
SDL_GPUTransferBufferLocation src = {
.transfer_buffer = transfer_buffer,
.offset = 0,
};
SDL_GPUBufferRegion dst = {
.buffer = group->buffer,
.offset = 0,
.size = instance_data_buf_size,
};
SDL_UploadToGPUBuffer(copy_pass, &src, &dst, false);
SDL_ReleaseGPUTransferBuffer(device, transfer_buffer);
}
void UpdateQuadGroup(QuadGroup* group) {
UpdateSingleQuad(group->single_quad);
Uint64 cur_tick = SDL_GetTicks();
Uint64 delta_ticks = cur_tick - group->last_tick;
float delta_time = (float)delta_ticks / 1000.0;
group->last_tick = cur_tick;
for (size_t i = 0; i < group->instance_count; i++) {
QuadInstanceState* state = &group->states[i];
float angle = state->angle;
state->angle = angle + delta_time * state->speed;
group->instances[i].position[0] = state->origin[0] + (SDL_cos(angle) * state->radius);
group->instances[i].position[1] = state->origin[1] + (SDL_sin(angle) * state->radius);
}
}
void RenderQuadGroup(QuadGroup* group,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPURenderPass* render_pass) {
RenderSingleQuad(group->single_quad, cmdbuf, render_pass, &group->buffer, 1,
group->instance_count);
}
Here we are creating two buffers: one to keep track of positions and the other to keep track of the state. The second one will only live in RAM and won’t be transfered to the GPU. For the first one we will need to update the iteration function to include a new copy pass:
In main.c:
typedef struct {
SDL_Window* window;
SDL_GPUDevice* device;
SDL_GPUViewport viewport;
// our resources
SDL_GPUGraphicsPipeline* flat_color_pipeline;
QuadGroup* quad_group;
} ExampleApp;
// Later, in Create:
// ...
// create resources
ShaderOptions vert_shader_opts = {0};
vert_shader_opts.filename = "flat-color.vs.spirv";
vert_shader_opts.stage = SDL_GPU_SHADERSTAGE_VERTEX;
vert_shader_opts.storage_buffer_count = 1; // <- ADD THIS ONE
// ...
// Remove the quad creation and use this one:
app->quad_group = CreateQuadGroup(app->device, 50);
if (app->quad_group == NULL) {
SDL_Log("Error: failed to create group: %s", SDL_GetError());
return SDL_APP_FAILURE;
}
// Initial upload (static data):
SDL_GPUCommandBuffer* cmdbuf = SDL_AcquireGPUCommandBuffer(app->device);
if (cmdbuf == NULL) {
SDL_Log("Error: failed to get initial command buffer: %s", SDL_GetError());
return SDL_APP_FAILURE;
}
SDL_GPUCopyPass* static_data_copy_pass = SDL_BeginGPUCopyPass(cmdbuf);
{
if (static_data_copy_pass == NULL) {
SDL_Log("Error: failed to get initial copy pass: %s", SDL_GetError());
return SDL_APP_FAILURE;
}
// Also updates the vertex buffer for single quad:
UploadQuadGroupStatic(app->quad_group, app->device, static_data_copy_pass);
}
SDL_EndGPUCopyPass(static_data_copy_pass);
SDL_SubmitGPUCommandBuffer(cmdbuf);
Later, in our iteration function:
// Update everything, including camera, positions, etc...
UpdateQuadGroup(app->quad_group);
// Copy instance data and render
SDL_GPUCommandBuffer* cmdbuf = SDL_AcquireGPUCommandBuffer(app->device);
if (cmdbuf == NULL) {
SDL_Log("Error: SDL_AcquireGPUCommandBuffer(): %s", SDL_GetError());
return SDL_APP_FAILURE;
}
SDL_GPUCopyPass* copy_pass = SDL_BeginGPUCopyPass(cmdbuf);
{
// Upload dynamic data
UploadQuadGroupFrame(app->quad_group, app->device, copy_pass);
}
SDL_EndGPUCopyPass(copy_pass);
SDL_SubmitGPUCommandBuffer(cmdbuf);
cmdbuf = SDL_AcquireGPUCommandBuffer(app->device);
if (cmdbuf == NULL) {
SDL_Log("Error: SDL_AcquireGPUCommandBuffer(): %s", SDL_GetError());
return SDL_APP_FAILURE;
}
SDL_GPUTexture* swapchain_texture = NULL;
if (!SDL_WaitAndAcquireGPUSwapchainTexture(cmdbuf, app->window, &swapchain_texture, NULL, NULL)) {
SDL_Log("Warning: could not acquire GPU swapchain texture");
}
You will notice that we are acquiring two command buffers, one for copying and other for rendering, this is not required but it helped me to debug an issue using RenderDoc.
Finally, don’t forget to update CMakeLists to include the new quad_group.c file:
target_sources(slang-sdl3-example PRIVATE shader.c texture.c quad.c quad_group.c main.c)
We can now compile (including the shaders!) and run everything. If there is no problems, then we should be able to see something like this:
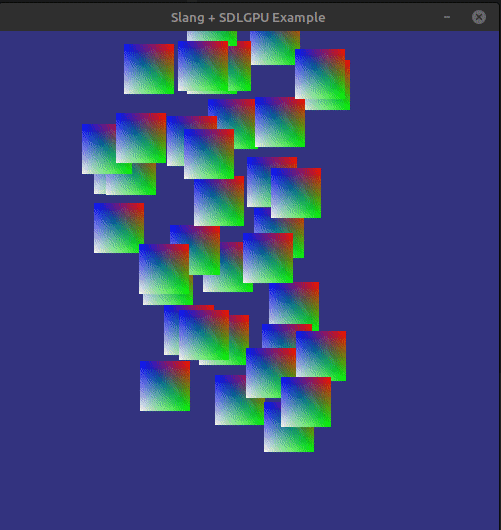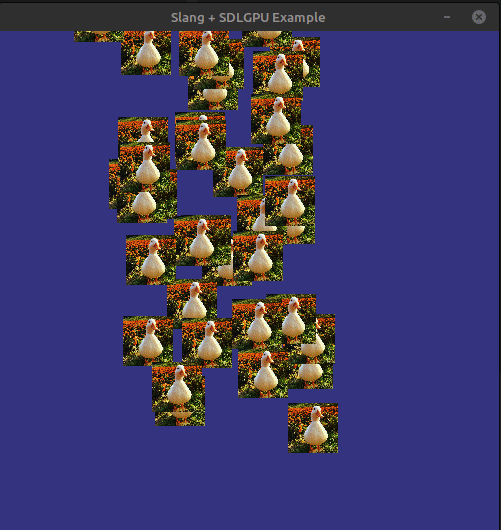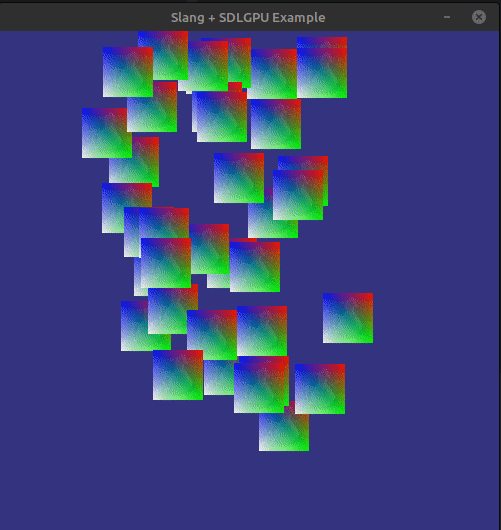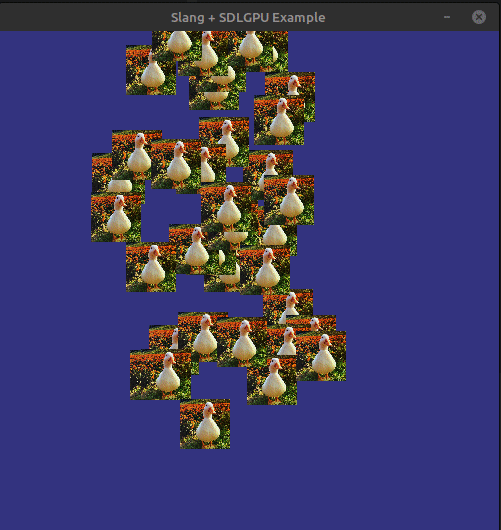
Next steps
Awesome! we now got storage buffers working for vertex shaders, the work is the same for fragments shaders except
that you’ll need to bind the set in layout to the proper value. Next chapter we will be
creating and dispatching compute shaders written in slang.
Happy coding.