Introduction
This post belongs to a series, you can find other parts here
The source code will be available on github.com/cedmundo/slang-sdl3-example, feel free to fork it and use it as you find suitable in your projects.
Compute shaders
Compute shaders allow us to execute programs in multiple threads within the GPU, they work similary to Vertex/Fragment shaders, except that we can decide how to dispatch them in the compute pass.
We must change many things in our code to support them, mostly because we can
re-arange the general architecture to improve a little bit the structure. First,
we are going to extract the pipeline creation from shader.c/h and put it into
A new module called pipeline, first let’s create pipeline.h:
#ifndef PIPELINE_H
#define PIPELINE_H
#include <SDL3/SDL_gpu.h>
SDL_GPUComputePipeline* CreateQuadComputePipeline(SDL_GPUDevice* device, const char* cs_filename);
SDL_GPUGraphicsPipeline* CreateQuadGraphicsPipeline(SDL_GPUDevice* device,
SDL_Window* window,
const char* vs_filename,
const char* fs_filename);
#define QUAD_COMPUTE_THREAD_COUNT_X 64
#define QUAD_COMPUTE_THREAD_COUNT_Y 1
#define QUAD_COMPUTE_THREAD_COUNT_Z 1
#endif /* PIPELINE_H */
The implementation goes as follows in pipeline.c:
#include "pipeline.h"
#include "shader.h"
#include <SDL3/SDL_filesystem.h>
#include <SDL3/SDL_gpu.h>
#include <SDL3/SDL_iostream.h>
#include <SDL3/SDL_log.h>
#include <SDL3/SDL_stdinc.h>
SDL_GPUComputePipeline* CreateQuadComputePipeline(SDL_GPUDevice* device, const char* cs_filename) {
char cs_path[255] = {0};
SDL_strlcat(cs_path, SDL_GetBasePath(), 255);
SDL_strlcat(cs_path, cs_filename, 255);
size_t code_len = 0;
Uint8* code_buf = SDL_LoadFile(cs_path, &code_len);
if (code_buf == NULL) {
return NULL;
}
SDL_GPUComputePipelineCreateInfo create_info = {0};
create_info.code = code_buf;
create_info.code_size = code_len;
create_info.num_uniform_buffers = 1; // time and quad count
create_info.num_readwrite_storage_buffers = 2; // states and positions
create_info.entrypoint = "main";
create_info.threadcount_x = QUAD_COMPUTE_THREAD_COUNT_X;
create_info.threadcount_y = QUAD_COMPUTE_THREAD_COUNT_Y;
create_info.threadcount_z = QUAD_COMPUTE_THREAD_COUNT_Z;
create_info.format = SDL_GPU_SHADERFORMAT_SPIRV;
SDL_GPUComputePipeline* pipeline = SDL_CreateGPUComputePipeline(device, &create_info);
SDL_free(code_buf);
return pipeline;
}
SDL_GPUGraphicsPipeline* CreateQuadGraphicsPipeline(SDL_GPUDevice* device,
SDL_Window* window,
const char* vs_filename,
const char* fs_filename) {
SDL_GPUGraphicsPipeline* pipeline = NULL;
ShaderOptions vert_options = {0};
vert_options.filename = vs_filename;
vert_options.stage = SDL_GPU_SHADERSTAGE_VERTEX;
vert_options.storage_buffer_count = 1;
SDL_GPUShader* vert_shader = LoadShader(device, vert_options);
if (vert_shader == NULL) {
SDL_Log("Error: failed to load shader: %s %s", vert_options.filename, SDL_GetError());
goto terminate;
}
ShaderOptions frag_options = {0};
frag_options.filename = fs_filename;
frag_options.stage = SDL_GPU_SHADERSTAGE_FRAGMENT;
frag_options.uniform_buffer_count = 1;
frag_options.sampler_count = 1;
SDL_GPUShader* frag_shader = LoadShader(device, frag_options);
if (frag_shader == NULL) {
SDL_Log("Error: failed to load shader: %s %s", frag_options.filename, SDL_GetError());
goto terminate;
}
// standard blending for this shader
SDL_GPUColorTargetBlendState blend_state = {0};
blend_state.enable_blend = true;
blend_state.src_color_blendfactor = SDL_GPU_BLENDFACTOR_ONE;
blend_state.dst_color_blendfactor = SDL_GPU_BLENDFACTOR_ONE_MINUS_SRC_ALPHA;
blend_state.color_blend_op = SDL_GPU_BLENDOP_ADD;
blend_state.src_alpha_blendfactor = SDL_GPU_BLENDFACTOR_ONE;
blend_state.dst_alpha_blendfactor = SDL_GPU_BLENDFACTOR_ONE_MINUS_SRC_ALPHA;
blend_state.alpha_blend_op = SDL_GPU_BLENDOP_ADD;
// color configuration with blend state
SDL_GPUColorTargetDescription color_desc = {0};
color_desc.format = SDL_GetGPUSwapchainTextureFormat(device, window);
color_desc.blend_state = blend_state;
// this are the targets to render (the swapchain texture)
SDL_GPUGraphicsPipelineTargetInfo color_target_info = {0};
color_target_info.num_color_targets = 1;
color_target_info.color_target_descriptions = (SDL_GPUColorTargetDescription[]){color_desc};
// finally we can create the actual pipeline
SDL_GPUGraphicsPipelineCreateInfo pipeline_create_info = {0};
pipeline_create_info.target_info = color_target_info;
pipeline_create_info.fragment_shader = frag_shader;
pipeline_create_info.vertex_shader = vert_shader;
pipeline_create_info.primitive_type = SDL_GPU_PRIMITIVETYPE_TRIANGLELIST;
pipeline_create_info.vertex_input_state = (SDL_GPUVertexInputState){
.num_vertex_attributes = 3,
.vertex_attributes =
(SDL_GPUVertexAttribute[]){
{.buffer_slot = 0,
.format = SDL_GPU_VERTEXELEMENTFORMAT_FLOAT3,
.location = 0,
.offset = 0},
{.buffer_slot = 1,
.format = SDL_GPU_VERTEXELEMENTFORMAT_FLOAT3,
.location = 1,
.offset = 0},
{.buffer_slot = 2,
.format = SDL_GPU_VERTEXELEMENTFORMAT_FLOAT2,
.location = 2,
.offset = 0},
},
.num_vertex_buffers = 3,
.vertex_buffer_descriptions =
(SDL_GPUVertexBufferDescription[]){
{.slot = 0,
.input_rate = SDL_GPU_VERTEXINPUTRATE_VERTEX,
.instance_step_rate = 0,
.pitch = sizeof(float) * 3},
{.slot = 1,
.input_rate = SDL_GPU_VERTEXINPUTRATE_VERTEX,
.instance_step_rate = 0,
.pitch = sizeof(float) * 3},
{.slot = 2,
.input_rate = SDL_GPU_VERTEXINPUTRATE_VERTEX,
.instance_step_rate = 0,
.pitch = sizeof(float) * 2},
},
};
pipeline = SDL_CreateGPUGraphicsPipeline(device, &pipeline_create_info);
terminate:
if (vert_shader != NULL) {
SDL_ReleaseGPUShader(device, vert_shader);
}
if (frag_shader != NULL) {
SDL_ReleaseGPUShader(device, frag_shader);
}
return pipeline;
}
Also, we should remove CreatePipeline from both shader.h and shader.c. Don’t
forget to add the new module to CMakeLists.txt:
target_sources(slang-sdl3-example PRIVATE
shader.c
pipeline.c # <- Add this one!
texture.c
quad.c
quad_group.c
main.c)
The idea is to use Compute Shaders to calculate the positions of our group of quads.
But this requires to update the quad_group module a lot.
For quad_group.h:
#ifndef QUAD_GROUP_H
#define QUAD_GROUP_H
#include <SDL3/SDL_gpu.h>
#include "quad.h"
typedef struct {
float position[2];
} QuadInstanceData;
typedef struct {
float origin[2];
float angle;
float speed;
float radius;
float padding0;
} QuadInstanceState;
typedef struct {
float delta_time;
Uint32 span_start;
Uint32 span_end;
float padding0;
} UniformCData;
typedef struct {
SingleQuad* single_quad;
size_t instance_count;
Uint64 last_tick;
size_t workgroup_size;
size_t required_workgroups;
SDL_GPUBuffer* buffers[2];
} QuadGroup;
QuadGroup* CreateQuadGroup(SDL_GPUDevice* device, size_t instance_count);
void DestroyQuadGroup(QuadGroup* group, SDL_GPUDevice* device);
void UploadQuadGroupStatic(QuadGroup* group, SDL_GPUDevice* device, SDL_GPUCopyPass* copy_pass);
void UpdateQuadGroup(QuadGroup* group,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPUComputePipeline* pipeline);
void RenderQuadGroup(QuadGroup* group,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPURenderPass* render_pass);
#endif /* QUAD_GROUP_H */
As we can see, we are adding a SDL_GPUComputePipeline as argument for quad group update. We also
removed the UploadQuadGroupFrame as is no longer needed. The new QuadGroup now only
contains general information about the capacity, and also tracks two GPU buffers that we will
be initializing later.
An important note here is to see the padding0 fields, those exist to keep the layout compatible
with layout 140 (see slang documentation). Otherwise we would have aligment issues. We also
need to allocate our buffers aligned to 16 bytes. In previous sections we have not enforced
this because it is mostly done automatically, but there will be moments that is not done
by default. You can use SDL_ALIGNED(X) to align a stack variable, or SDL_aligned_alloc(align, size)
to allocate aligned memory on heap.
The implementation in quad_group.c is:
#include "quad_group.h"
#include "pipeline.h"
#include "quad.h"
#include <SDL3/SDL_gpu.h>
#include <SDL3/SDL_log.h>
#include <SDL3/SDL_stdinc.h>
#include <SDL3/SDL_timer.h>
#define BUFFER_INDEX_STATES (0)
#define BUFFER_INDEX_POSITIONS (1)
static float v_remap(float value, float high1, float low1, float high2, float low2);
QuadGroup* CreateQuadGroup(SDL_GPUDevice* device, size_t instance_count) {
QuadGroup* group = SDL_malloc(sizeof(QuadGroup));
if (group == NULL) {
return NULL;
}
group->last_tick = SDL_GetTicks();
group->instance_count = instance_count;
group->single_quad = CreateSingleQuad(device);
if (group->single_quad == NULL) {
DestroyQuadGroup(group, device);
return NULL;
}
group->workgroup_size = QUAD_COMPUTE_THREAD_COUNT_X;
group->required_workgroups =
(size_t)SDL_ceil((double)group->instance_count / group->workgroup_size);
// We want two buffers: first one is for states, second one to pass it to shaders
size_t states_buf_size = sizeof(QuadInstanceState) * instance_count;
SDL_GPUBufferCreateInfo states_buffer_create_info = {0};
states_buffer_create_info.size = states_buf_size;
states_buffer_create_info.usage =
SDL_GPU_BUFFERUSAGE_COMPUTE_STORAGE_WRITE | SDL_GPU_BUFFERUSAGE_COMPUTE_STORAGE_WRITE;
group->buffers[BUFFER_INDEX_STATES] = SDL_CreateGPUBuffer(device, &states_buffer_create_info);
// This buffer we want compute to write AND also read from graphics
size_t positions_buf_size = sizeof(QuadInstanceData) * instance_count;
SDL_GPUBufferCreateInfo positions_buffer_create_info = {0};
positions_buffer_create_info.size = positions_buf_size;
positions_buffer_create_info.usage =
SDL_GPU_BUFFERUSAGE_COMPUTE_STORAGE_WRITE | SDL_GPU_BUFFERUSAGE_GRAPHICS_STORAGE_READ;
group->buffers[BUFFER_INDEX_POSITIONS] =
SDL_CreateGPUBuffer(device, &positions_buffer_create_info);
return group;
}
void DestroyQuadGroup(QuadGroup* group, SDL_GPUDevice* device) {
if (group == NULL) {
return;
}
SDL_ReleaseGPUBuffer(device, group->buffers[BUFFER_INDEX_STATES]);
SDL_ReleaseGPUBuffer(device, group->buffers[BUFFER_INDEX_POSITIONS]);
if (group->single_quad != NULL) {
DestroySingleQuad(group->single_quad, device);
}
SDL_free(group);
}
void UploadQuadGroupStatic(QuadGroup* group, SDL_GPUDevice* device, SDL_GPUCopyPass* copy_pass) {
// Upload the single quad mesh and texture data
UploadSingleQuad(group->single_quad, device, copy_pass);
// Initialize initial states
size_t instance_count = group->instance_count;
size_t states_buffer_size = sizeof(QuadInstanceState) * group->instance_count;
// We use `SDL_aligned_alloc` to ensure that the memory is safely copied.
QuadInstanceState* states = SDL_aligned_alloc(16, states_buffer_size);
if (states == NULL) {
SDL_Log("Error: could not create temp buffer to upload initialization data");
return;
}
// Randomize staring state
for (size_t i = 0; i < instance_count; i++) {
float x = v_remap(SDL_randf(), 1.0f, 0.0f, 0.8f, -0.8f);
float y = v_remap(SDL_randf(), 1.0f, 0.0f, 0.8f, -0.8f);
float r = v_remap(SDL_randf(), 1.0f, 0.0f, 0.1f, 0.3f);
float s = SDL_randf() > 0.5 ? -0.4f : 0.4f;
states[i].origin[0] = x;
states[i].origin[1] = y;
states[i].speed = s;
states[i].angle = 0.0f;
states[i].radius = r;
}
// Copy starting states to the first buffer
SDL_GPUTransferBufferCreateInfo transfer_buffer_create_info = {0};
transfer_buffer_create_info.size = states_buffer_size;
transfer_buffer_create_info.usage = SDL_GPU_TRANSFERBUFFERUSAGE_UPLOAD;
SDL_GPUTransferBuffer* transfer_buffer =
SDL_CreateGPUTransferBuffer(device, &transfer_buffer_create_info);
void* gpu_staging = SDL_MapGPUTransferBuffer(device, transfer_buffer, false);
SDL_memcpy(gpu_staging, states, states_buffer_size);
SDL_UnmapGPUTransferBuffer(device, transfer_buffer);
SDL_GPUTransferBufferLocation src = {
.transfer_buffer = transfer_buffer,
.offset = 0,
};
SDL_GPUBufferRegion dst = {
.buffer = group->buffers[0],
.offset = 0,
.size = states_buffer_size,
};
SDL_aligned_free(states);
SDL_UploadToGPUBuffer(copy_pass, &src, &dst, false);
SDL_ReleaseGPUTransferBuffer(device, transfer_buffer);
}
void UpdateQuadGroup(QuadGroup* group,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPUComputePipeline* pipeline) {
UpdateSingleQuad(group->single_quad);
Uint64 cur_tick = SDL_GetTicks();
Uint64 delta_ticks = cur_tick - group->last_tick;
float delta_time = (float)delta_ticks / 1000.0;
group->last_tick = cur_tick;
SDL_GPUStorageBufferReadWriteBinding buffer_bindings[2] = {
(SDL_GPUStorageBufferReadWriteBinding){
.buffer = group->buffers[BUFFER_INDEX_STATES],
.cycle = false,
},
(SDL_GPUStorageBufferReadWriteBinding){
.buffer = group->buffers[BUFFER_INDEX_POSITIONS],
.cycle = false,
},
};
SDL_GPUComputePass* compute_pass = SDL_BeginGPUComputePass(cmdbuf, NULL, 0, buffer_bindings, 2);
{
SDL_BindGPUComputePipeline(compute_pass, pipeline);
SDL_BindGPUComputeStorageBuffers(compute_pass, 0, group->buffers, 2);
const SDL_ALIGNED(16) UniformCData uniforms = {
.delta_time = delta_time,
.span_start = 0,
.span_end = (Uint32)group->instance_count,
};
SDL_PushGPUComputeUniformData(cmdbuf, 0, &uniforms, sizeof(UniformCData));
SDL_DispatchGPUCompute(compute_pass, (Uint32)group->required_workgroups, 1, 1);
}
SDL_EndGPUComputePass(compute_pass);
}
void RenderQuadGroup(QuadGroup* group,
SDL_GPUCommandBuffer* cmdbuf,
SDL_GPURenderPass* render_pass) {
// We pass only the last buffer since it is where positions are stored
RenderSingleQuad(group->single_quad, cmdbuf, render_pass, &group->buffers[BUFFER_INDEX_POSITIONS],
1, group->instance_count);
}
static float v_remap(float value, float high1, float low1, float high2, float low2) {
return low2 + (value - low1) * (high2 - low2) / (high1 - low1);
}
Here, a lot has changed:
- We create two buffers: one for states and another for positions in the GPU.
- There is only one copy pass: at the begining we copy a generated state into the state buffer.
- In update function, we bind and dispatch our shader (which have not been written just yet).
- We re-use the output from compute pass as a read buffer for render pass, note that it must
be specified in the pipeline (see
pipeline.c).
Now, we can write our compute shader.
In assets/shaders/quad-group.slang:
struct UniformData {
float delta_time;
uint32_t span_start;
uint32_t span_end;
};
struct QuadState {
float2 origin;
float angle;
float speed;
float radius;
};
// Layout here: https://wiki.libsdl.org/SDL3/SDL_CreateGPUComputePipeline
layout(set = 2) ParameterBlock<UniformData> uniforms;
layout(set = 1, binding = 0) RWStructuredBuffer<QuadState> io_states;
layout(set = 1, binding = 1) RWStructuredBuffer<float2> o_positions;
[shader("compute")]
[numthreads(64, 1, 1)]
void main(uint3 threadId: SV_DispatchThreadID) {
uint index = threadId.x;
if (index >= uniforms.span_end) {
return;
}
QuadState state = io_states[index];
float angle = state.angle;
state.angle = angle + uniforms.delta_time * state.speed;
io_states[index] = state;
o_positions[index] = float2(state.origin.x + cos(angle) * state.radius,
state.origin.y + sin(angle) * state.radius);
}
This does more or less the same we were doing in the CPU: getting the previous state, updating it and writting the new position to a buffer. Note the layout directives because they are really important, otherwise this shader won’t work and the validation layer will yell at us.
Also, you should compile it too:
$ slangc assets/shaders/quad-group.slang -o cmake-build-debug/quad-group.spirv -entry main -target spirv
At last, we update main.c, first, fix the headers and definitions:
#include "pipeline.h"
#include "quad_group.h"
#define WINDOW_TITLE "Slang + SDLGPU Example"
#define WINDOW_HEIGHT 500
#define WINDOW_WIDTH 500
#define QUAD_COUNT (1e5)
typedef struct {
SDL_Window* window;
SDL_GPUDevice* device;
SDL_GPUViewport viewport;
// our resources
SDL_GPUGraphicsPipeline* quad_g_pipeline;
SDL_GPUComputePipeline* quad_c_pipeline;
QuadGroup* quad_group;
} ExampleApp;
Then, update the resource creation since pipeline process changed:
// create resources
app->quad_c_pipeline = CreateQuadComputePipeline(app->device, "quad-group.spirv");
if (app->quad_c_pipeline == NULL) {
SDL_Log("Error: failed to create compute pipeline: %s", SDL_GetError());
return SDL_APP_FAILURE;
}
app->quad_g_pipeline = CreateQuadGraphicsPipeline(app->device, app->window, "flat-color.vs.spirv",
"flat-color.fs.spirv");
if (app->quad_g_pipeline == NULL) {
SDL_Log("Error: failed to create graphics pipeline: %s", SDL_GetError());
return SDL_APP_FAILURE;
}
app->quad_group = CreateQuadGroup(app->device, QUAD_COUNT);
if (app->quad_group == NULL) {
SDL_Log("Error: failed to create group: %s", SDL_GetError());
return SDL_APP_FAILURE;
}
Before chaning iterate, don’t forget to update quit:
void SDL_AppQuit(void* appstate, SDL_AppResult result) {
ExampleApp* app = (ExampleApp*)appstate;
if (app == NULL) {
return;
}
if (app->quad_group != NULL) {
DestroyQuadGroup(app->quad_group, app->device);
}
if (app->quad_g_pipeline != NULL) {
SDL_ReleaseGPUGraphicsPipeline(app->device, app->quad_g_pipeline);
}
if (app->quad_c_pipeline != NULL) {
SDL_ReleaseGPUComputePipeline(app->device, app->quad_c_pipeline);
}
if (app->device != NULL) {
SDL_DestroyGPUDevice(app->device);
}
if (app->window != NULL) {
SDL_DestroyWindow(app->window);
}
SDL_Log("Info: Terminated with result: %d", result);
}
Now, we can focus on the iterate function:
SDL_AppResult SDL_AppIterate(void* appstate) {
ExampleApp* app = (ExampleApp*)appstate;
SDL_assert(app != NULL);
// Copy instance data and render
SDL_GPUCommandBuffer* cmdbuf = SDL_AcquireGPUCommandBuffer(app->device);
if (cmdbuf == NULL) {
SDL_Log("Error: SDL_AcquireGPUCommandBuffer(): %s", SDL_GetError());
return SDL_APP_FAILURE;
}
SDL_GPUTexture* swapchain_texture = NULL;
if (!SDL_WaitAndAcquireGPUSwapchainTexture(cmdbuf, app->window, &swapchain_texture, NULL, NULL)) {
SDL_Log("Warning: could not acquire GPU swapchain texture");
}
// Update everything, including camera, positions, etc...
UpdateQuadGroup(app->quad_group, cmdbuf, app->quad_c_pipeline);
if (swapchain_texture != NULL) {
SDL_GPUColorTargetInfo color_target_info = {0};
color_target_info.texture = swapchain_texture;
color_target_info.clear_color = (SDL_FColor){0.2f, 0.2f, 0.5f, 1.0f};
color_target_info.load_op = SDL_GPU_LOADOP_CLEAR;
color_target_info.store_op = SDL_GPU_STOREOP_STORE;
SDL_GPURenderPass* render_pass = SDL_BeginGPURenderPass(cmdbuf, &color_target_info, 1, NULL);
{
SDL_SetGPUViewport(render_pass, &app->viewport);
// Bind flat color pipeline
SDL_BindGPUGraphicsPipeline(render_pass, app->quad_g_pipeline);
{
// Render the quad using the bound pipeline
RenderQuadGroup(app->quad_group, cmdbuf, render_pass);
}
SDL_BindGPUGraphicsPipeline(render_pass, NULL);
}
SDL_EndGPURenderPass(render_pass);
}
SDL_SubmitGPUCommandBuffer(cmdbuf);
return SDL_APP_CONTINUE;
}
The main changes is that we are not doing a copy pass anymore, we are also updating the quad group by passing the quad pipeline.
If we build a run everything (do not forget the shaders!). We should be doing something like this:
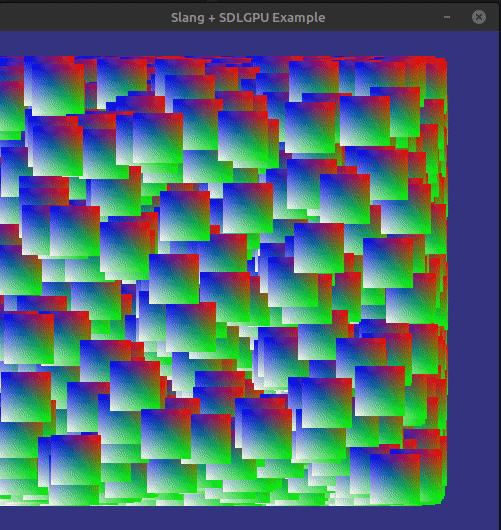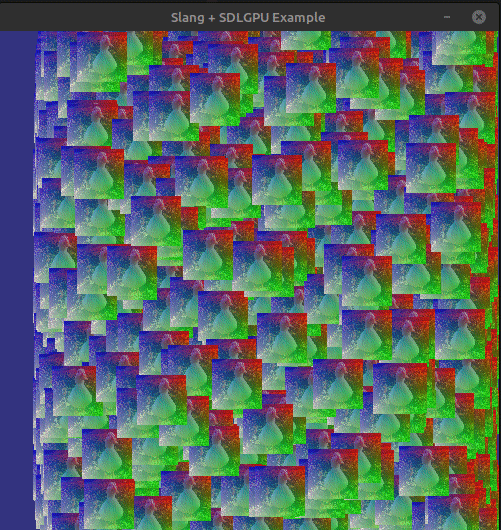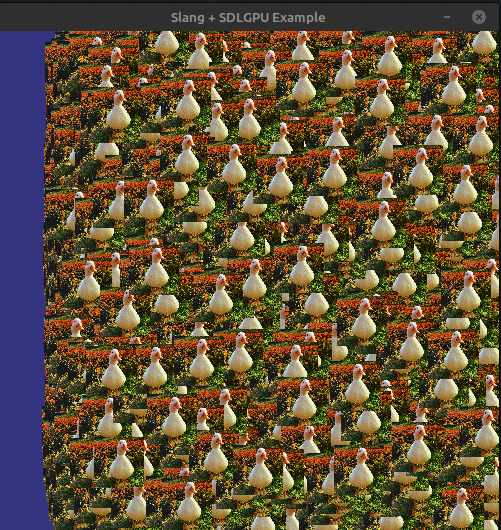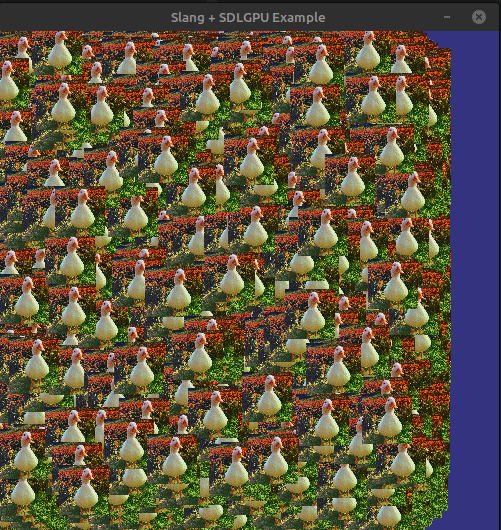
And thats it!
Next Steps
The last few posts have been a little bit hand-waving about the implementation details, the reason is that I tried to focus a little bit more in the intergation instead of the explanation of what is each component. Despite this, the project is quite simple and can be implemented in a weekend, the key about integrating SDL3 with slang is to keep track of the layout and memory aligment.
I’ll be adding a few extras here. But this is the end of the series.
Thank you, Happy coding.